 私たちはウクライナの友人や同僚を支持します。困っているウクライナを支援するには、
私たちはウクライナの友人や同僚を支持します。困っているウクライナを支援するには、サービスパフォーマンスモニタリング (SPM)
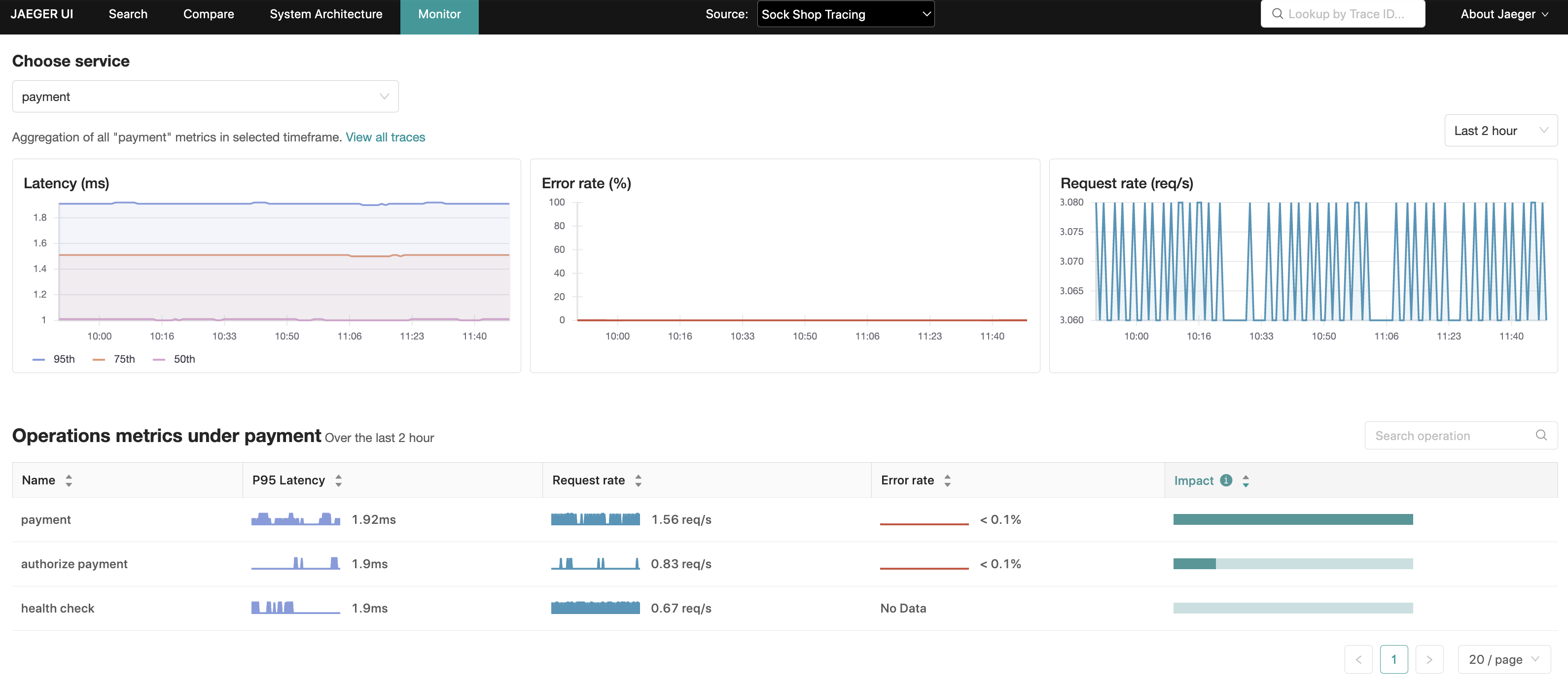
Jaeger UI の「モニター」タブに表示されるこの機能の動機は、サービスやオペレーションの名前を事前に知らなくても、興味深いトレース(例えば、高い QPS、遅いまたはエラーのあるリクエスト)を特定するのに役立つことです。
これは基本的に、スパンデータを集計して RED (リクエスト、エラー、所要時間) メトリクスを生成することで実現されます。
潜在的なユースケースには、以下が含まれます。
- 組織全体、またはリクエストチェーン内の既知の依存サービスに対するデプロイ後の健全性チェック。
- 問題が警告された場合の監視と根本原因の特定。
- Jaeger UI の新規ユーザー向けのより良いオンボーディングエクスペリエンス。
- QPS、エラー、レイテンシーの長期的なトレンド分析。
- キャパシティプランニング。
UI 機能の概要
「モニター」タブには、サービスレベルの集計と、サービス内のオペレーションレベルの集計として、リクエストレート、エラーレート、および所要時間 (P95、P75、および P50) が表示されます。これらは RED メトリクスとしても知られています。
オペレーションレベルの集計内では、レイテンシーとリクエストレートの積として計算される「影響」メトリクスは、毎日のバッチジョブなど自然にレイテンシープロファイルが高いオペレーションを除外したり、逆にレイテンシーランキングは低いが RPS (秒あたりのリクエスト数) が高いオペレーションを強調表示したりするために使用できる別のシグナルです。
これらの集計から、Jaeger UI は関連するサービス、オペレーション、および遡及期間でトレース検索を事前に入力し、より興味深いトレースの検索範囲を絞り込むことができます。
はじめ方
ローカルで実行可能なセットアップは、Jaeger リポジトリ で入手でき、実行方法に関する手順も記載されています。
この機能には、トップメニューの「モニター」タブからアクセスできます。
このデモには、トレースデータを生成するマイクロサービスシミュレーターである Microsim が含まれています。
手動でトレースを生成する場合は、サンプルアプリ:HotROD を Docker を介して起動できます。docker run コマンドに必ず --net monitor_backend を含めてください。
アーキテクチャ
モニタータブ用に Jaeger がクエリする RED メトリクスは、OpenTelemetry Collector によって収集されたスパンデータの結果であり、その後、パイプライン内で構成された SpanMetrics Connector コンポーネントによって集計されます。
これらのメトリクスは、最終的に OpenTelemetry Collector (Prometheus エクスポーター経由) によって、Prometheus 互換のメトリクスストアにエクスポートされます。
これは「読み取り専用」機能であり、そのため、Jaeger Query コンポーネント (および All In One) のみに該当することを強調しておくことが重要です。
派生時系列
これはOpenTelemetry Collector の範囲内ですが、SpanMetrics Connector が、SPMをデプロイする際のキャパシティプランニングに役立つよう、メトリクスストレージに生成する追加のメトリクスと時系列を理解しておくことは価値があります。
メトリクス名、型、ラベル、時系列の概念を網羅したPrometheusのドキュメント を参照してください。このセクションの残りの部分で使用される用語です。
2つのメトリクス名が作成されます。
calls_total- 型: counter
- 説明: エラーのスパンを含む、スパンの総数をカウントします。呼び出し数は、
status_codeラベルによってエラーと区別されます。エラーは、ラベルstatus_code = "STATUS_CODE_ERROR"を持つ任意の時系列として識別されます。
[namespace_]duration_[units]- 型: histogram
- 説明: スパンの期間/レイテンシーのヒストグラム。内部では、Prometheusのヒストグラムは多数の時系列を作成します。説明のため、名前空間が設定されておらず、単位が
millisecondsであると仮定します。duration_milliseconds_count: ヒストグラム内のすべてのバケットにわたるデータポイントの合計数。duration_milliseconds_sum: すべてのデータポイント値の合計。duration_milliseconds_bucket: 各継続時間バケットに対して、le(以下) ラベルで識別されるn個の時系列のコレクション(nは継続時間バケットの数)。最小のleを持ち、le >= スパン期間のduration_milliseconds_bucketカウンターが、各スパンに対してインクリメントされます。
次の式は、作成される新しい時系列の数に関するガイダンスを提供することを目的としています。
num_status_codes * num_span_kinds * (1 + num_latency_buckets) * num_operations
Where:
num_status_codes = 3 max (typically 2: ok/error)
num_span_kinds = 6 max (typically 2: client/server)
num_latency_buckets = 17 default
デフォルト設定を仮定して、これらの数値を代入すると
max = 324 * num_operations
typical = 72 * num_operations
注
- spanmetricsコネクタで設定されたカスタムの継続時間バケット またはディメンション は、上記の計算を変更します。
- カスタムディメンションのクエリは、SPMではサポートされておらず、集計されます。
構成
SPMの有効化
SPM機能を有効にするには、次の構成が必要です。
- Jaeger UI
- Jaeger Query
METRICS_STORAGE_TYPE環境変数をprometheusに設定します。- オプション:
--prometheus.server-url(またはPROMETHEUS_SERVER_URL環境変数)を、PrometheusサーバーのURLに設定します。デフォルト: http://localhost:9090。 - オプション: SpanMetrics Connector を使用する場合は、
--prometheus.query.support-spanmetrics-connector=trueを設定して明示的に有効にします。これは、将来のデフォルトの動作になります。
API
gRPC/Protobuf
REDメトリクスをプログラムで取得する推奨される方法は、metricsquery.proto IDLファイルで定義されている jaeger.api_v2.metrics.MetricsQueryService gRPCエンドポイントを介する方法です。
HTTP JSON
Jaeger UIの[Monitor]タブで、視覚化のためのメトリクスを入力するために内部的に使用されます。
HTTP APIの詳細な仕様については、このREADMEファイル を参照してください。
トラブルシューティング
/metrics エンドポイントの確認
/metrics エンドポイントを使用すると、特定のサービスのスパンスパンが受信されたかどうかを確認できます。/metrics エンドポイントは、管理ポートから提供されます。Jaeger all-in-oneとqueryがそれぞれall-in-oneとjaeger-queryという名前のホストで利用可能であると仮定すると、以下はメトリクスを取得するためのサンプルcurl呼び出しです。
$ curl http://all-in-one:14269/metrics
$ curl http://jaeger-query:16687/metrics
最も関心のあるメトリクスは次のとおりです。
# all-in-one
jaeger_requests_total
jaeger_latency_bucket
# jaeger-query
jaeger_query_requests_total
jaeger_query_latency_bucket
これらのメトリクスにはそれぞれ、次の各操作のラベルが付いています。
get_call_rates
get_error_rates
get_latencies
get_min_step_duration
期待どおりに動作している場合、result="ok" ラベルが付いたメトリクスは増加し、result="err" は静的であるはずです。例
jaeger_query_requests_total{operation="get_call_rates",result="ok"} 18
jaeger_query_requests_total{operation="get_error_rates",result="ok"} 18
jaeger_query_requests_total{operation="get_latencies",result="ok"} 36
jaeger_query_latency_bucket{operation="get_call_rates",result="ok",le="0.005"} 5
jaeger_query_latency_bucket{operation="get_call_rates",result="ok",le="0.01"} 13
jaeger_query_latency_bucket{operation="get_call_rates",result="ok",le="0.025"} 18
jaeger_query_latency_bucket{operation="get_error_rates",result="ok",le="0.005"} 7
jaeger_query_latency_bucket{operation="get_error_rates",result="ok",le="0.01"} 13
jaeger_query_latency_bucket{operation="get_error_rates",result="ok",le="0.025"} 18
jaeger_query_latency_bucket{operation="get_latencies",result="ok",le="0.005"} 7
jaeger_query_latency_bucket{operation="get_latencies",result="ok",le="0.01"} 25
jaeger_query_latency_bucket{operation="get_latencies",result="ok",le="0.025"} 36
Prometheusサーバーに到達できないなどのPrometheusからメトリクスを読み取る際に問題がある場合、result="err" メトリクスが増加します。例
jaeger_query_requests_total{operation="get_call_rates",result="err"} 4
jaeger_query_requests_total{operation="get_error_rates",result="err"} 4
jaeger_query_requests_total{operation="get_latencies",result="err"} 8
この時点で、ログを確認すると、問題の根本原因をより深く理解できます。
Prometheusのクエリ
上記のJaegerメトリクスがPrometheusからの読み取りに成功したことを示している場合でも、グラフが空で表示されることがあります。この場合、これらのメトリクスのいずれかでPrometheusに直接クエリを実行します。
duration_bucketduration_milliseconds_bucketduration_seconds_bucketcallscalls_total
サービスがOpenTelemetry Collectorにスパンを発行するにつれて、これらのカウンターが増加しているはずです。
ログの表示
上記のメトリクスがPrometheusに存在していても、[Monitor]タブに表示されない場合は、JaegerがPrometheusに表示することを期待しているメトリクスと、実際に利用可能なメトリクスの間に不一致があることを意味します。
これは、次の環境変数を設定してログレベルを上げることで確認できます。
LOG_LEVEL=debug
次のようなログを出力します。
{
"level": "debug",
"ts": 1688042343.4464543,
"caller": "metricsstore/reader.go:245",
"msg": "Prometheus query results",
"results": "",
"query": "sum(rate(calls{service_name =~ \"driver\", span_kind =~ \"SPAN_KIND_SERVER\"}[10m])) by (service_name,span_name)",
"range":
{
"Start": "2023-06-29T12:34:03.081Z",
"End": "2023-06-29T12:39:03.081Z",
"Step": 60000000000
}
}
この例では、OpenTelemetry Collectorのprometheusexporterが、カウンターメトリクスに_totalサフィックスを追加し、ヒストグラムメトリクス(例:duration_milliseconds_bucket)内で継続時間の単位を追加する破壊的な変更を導入したとします。発見したように、Jaegerはcalls(およびduration_bucket)メトリクス名を検索していますが、OpenTelemetry Collectorはcalls_total(およびduration_milliseconds_bucket)を書き込んでいます。
この特定のケースでの解決策は、calls_totalとduration_milliseconds_bucketを検索することをJaegerに認識させるために、メトリクス名を正規化するようにJaegerに指示する環境変数を設定することです。例:
PROMETHEUS_QUERY_NORMALIZE_CALLS=true
PROMETHEUS_QUERY_NORMALIZE_DURATION=true
OpenTelemetry Collectorの設定の確認
エラーのスパンがJaegerに表示されていても、対応するエラーメトリクスがない場合は
- spanmetricsコネクタによって生成されたPrometheus内の生のメトリクス(上記にリストされている
calls、calls_total、duration_bucketなど)に、スパンが属するはずのメトリクスにstatus.codeラベルが含まれていることを確認します。 status.codeラベルがない場合は、OpenTelemetry Collector構成ファイル、特に次の構成の存在を確認してください。このラベルは、リクエストがエラーであるかどうかを判断するためにJaegerによって使用されます。exclude_dimensions: ['status.code']
OpenTelemetry Collectorの検査
上記のlatency_bucketとcalls_totalメトリクスが空の場合は、OpenTelemetry Collectorまたはその上流にある何らかの構成ミスである可能性があります。
トラブルシューティング中に尋ねるいくつかの質問は次のとおりです。
- OpenTelemetry Collectorは正しく構成されていますか?
- OpenTelemetry CollectorはPrometheusサーバーに到達できますか?
- サービスは OpenTelemetry Collector にスパンを送信していますか?
モニタータブにサービス/オペレーションが表示されない
モニタータブにサービス/オペレーションが表示されないが、Jaeger のトレース検索のサービスとオペレーションのドロップダウンメニューには表示される場合、一般的な原因として、メトリクスクエリで使用されるデフォルトの server スパン種別が挙げられます。
表示されていないサービス/オペレーションは、client など、server ではないスパン種別、あるいはさらに悪いことに、unspecified のスパン種別である可能性があります。したがって、これは計測データの品質の問題であり、計測によってスパン種別を設定する必要があります。
server スパン種別がデフォルトになっている理由は、server と client のスパン種別で、それぞれイングレとエグレスのスパンを二重にカウントすることを避けるためです。
メトリクスクエリ実行時に 403 エラーが発生する
ログに failed executing metrics query: client_error: client error: 403 のようなエラーが含まれている場合、Prometheus サーバーがベアラートークンを期待している可能性があります。
Jaeger Query (およびオールインワン) は、--prometheus.token-file コマンドラインパラメーター(または PROMETHEUS_TOKEN_FILE 環境変数)を介してメトリクスクエリでベアラートークンを渡すように構成できます。その値はベアラートークンを含むファイルのパスに設定します。